tldr: We’re reaching LLM routing’s halftime.
Over the past few years, “LLM routing” has been treated as traditional networking problem in gateway engineering for the AI era: reliably send requests to a model, stream tokens steadily, and keep latency, cost, and availability within an SLA. It worked — and it worked too well. So well that it’s getting platformized and standardized into a reusable industrial recipe.
So what’s suddenly different?
In one sentence: models are exploding in number; the traditional AI-gateway recipe now works — and it generalizes — so AI gateways are multiplying. Not just for a single provider, but across providers; not just for one deployment style, but across the whole chain — from cloud APIs to self-hosted inference clusters.
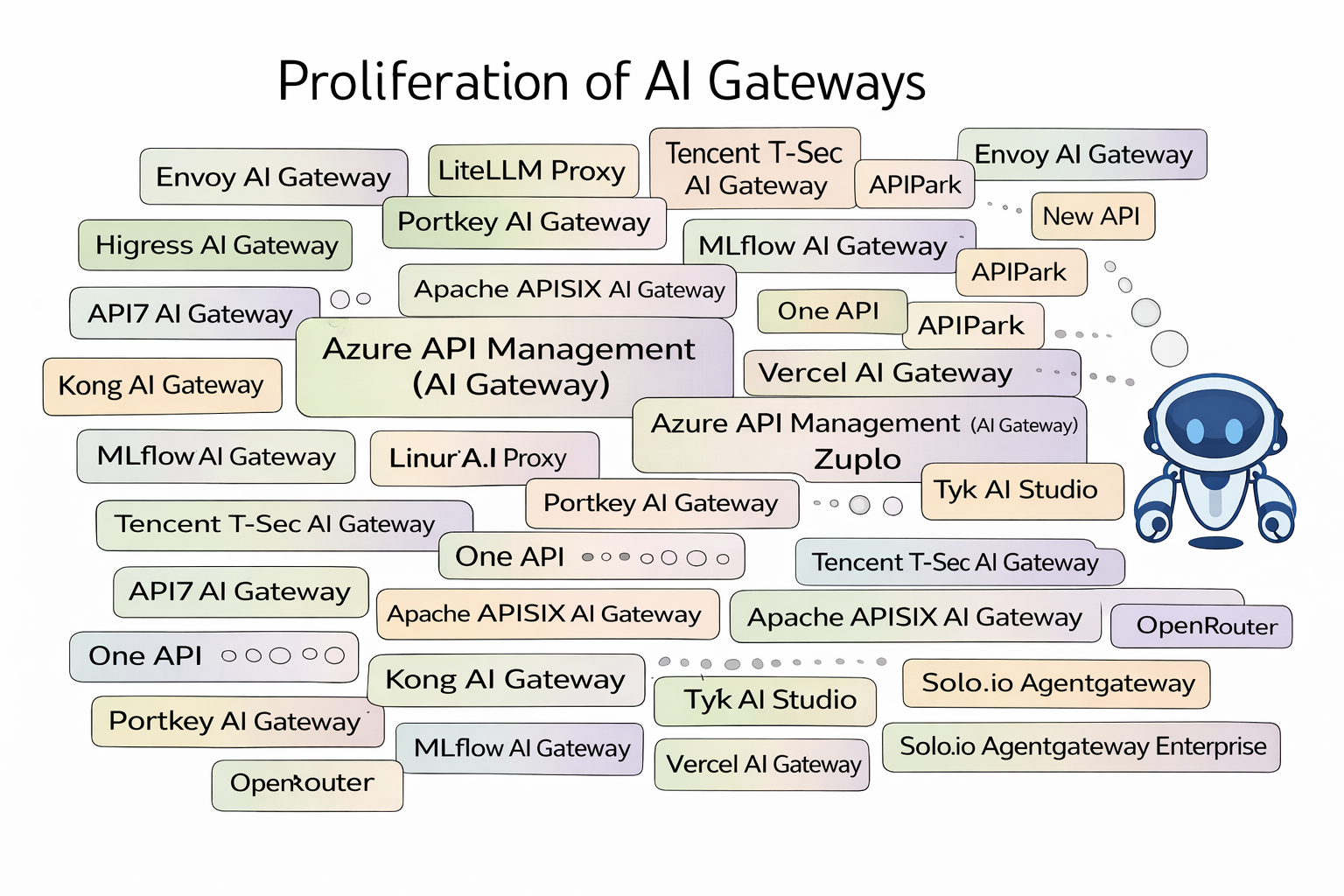
It’s getting hard to say “I built an AI gateway,” because you quickly realize what you built is almost the same thing everyone else built.
When a general recipe solves more and more problems, incremental methods get steamrolled by standardized pipelines. The game shifts from solving problems to defining problems. Evaluation becomes more important than adding more features in the same road.
I think the second half of LLM routing starts at the same moment: when innovation gets squeezed out, we should rethink what “routing” even means in the AI era.
The first half
To understand the first half, look at its winners.
In the world of LLM routing, what’s the most “useful,” most “shippable,” and most “sellable to enterprises”? The winners are a complete Traditional AI Gateway / Inference Gateway capability set — productized faster than anything else:
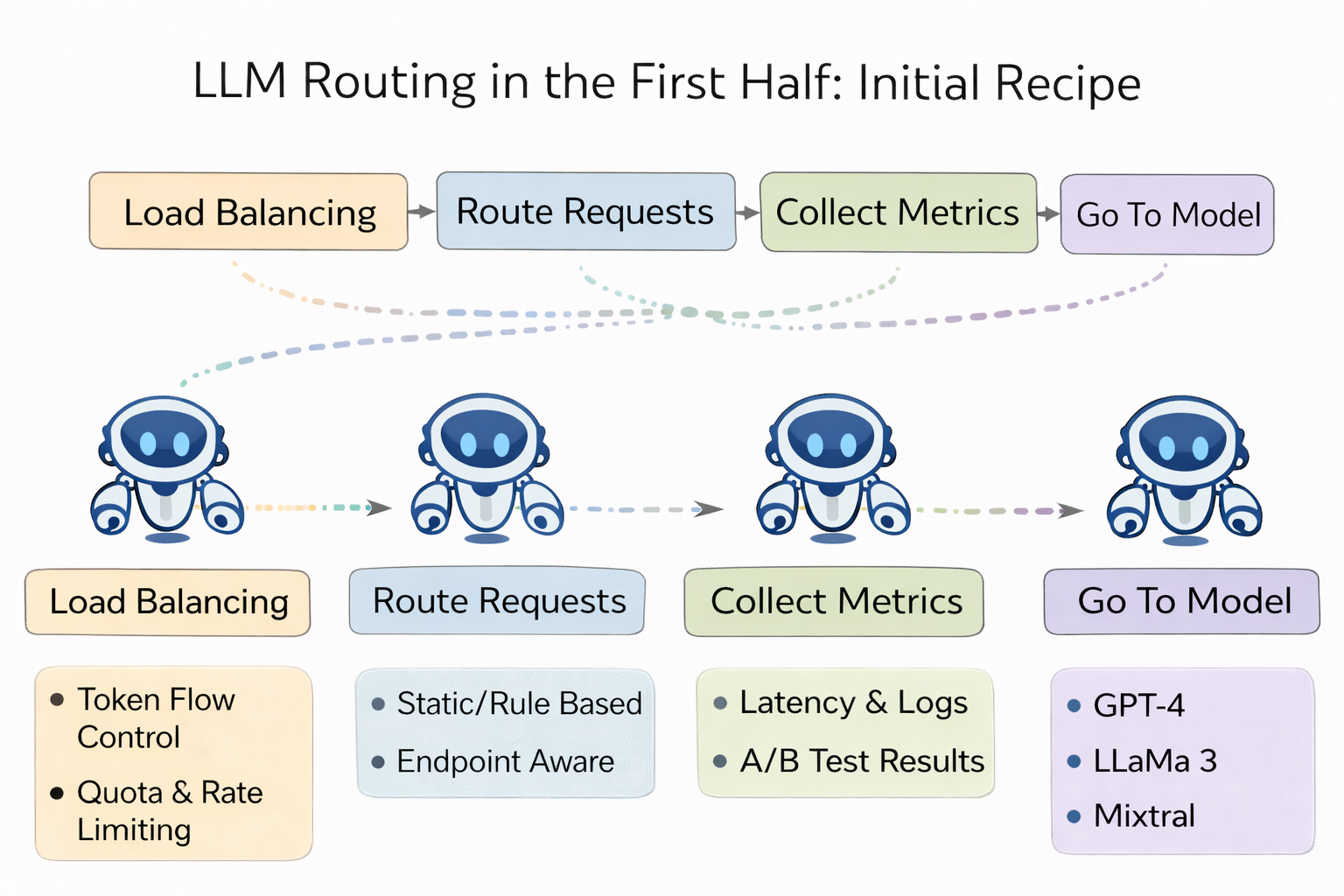
- Like a traditional API gateway: unify backend LLM services, handle auth, token quotas, rate limiting, circuit breaking & retries, failover, canary releases, A/B tests, and auditing.
- Like an inference engine: load-awareness, queues & priority, prefix caching, P/D disaggregation, and scheduling across endpoints.
These solved the first-half core problem: making LLMs behave like a manageable backend service.
They share one thing: routing decisions are mostly based on system state (health, load, price, SLA, tenant policy). Models are endpoints; requests are packets.
Sure, you can “pick a model.” But you don’t have to answer “why,” and you don’t have to own whether the task actually got done.
That was perfectly reasonable in the first half: when a system is just getting started, fast productization and reliability are the value.
The recipe
So what force kicks off the second half?
A brutal-but-true structural force: homogenization.
If you study multiple AI gateways seriously, you reach a very unromantic conclusion: they look extremely similar. Innovation space gets compressed into “plugin lists” and “product packaging.” It’s not that people aren’t smart — it’s that the first-half objective function naturally converges to the same engineering solution.
You almost always see the same recipe:
- A single unified entry point (usually an OpenAI-style API) that hides provider differences.
- Token-based quota & cost governance (otherwise finance can’t close the books).
- The reliability trio: retries, fallback, circuit breaking, plus canary/AB.
- Observability & audit: usage, cost, errors, latency, tenant attribution.
- Inference scheduling & optimization: queues, priorities, load-awareness, prefix caching and reuse.
That’s why it’s called a “recipe”: it’s general, replicable, and industrializable.
Once the recipe is established, the industry enters a familiar phase — the recipe crushes incremental methods.
So the question becomes sharp:
If the first-half recipe already works and gets increasingly standardized, what are we even playing in the second half? Just keep adding items to the plugin menu?
I don’t think so. Because the nature of what sits behind the routing layer has changed.
In the traditional API world, backend services are closer to deterministic systems: you call an API, it either succeeds or fails, and the semantics are relatively stable. Gateway traffic routing makes perfect sense.
But in the LLM world, backend services are generative — and increasingly agent-like: they reason, act, call tools, and change the external world. The “backend” is no longer a passive service. It’s an entity that makes decisions, makes mistakes, and can self-reinforce.
If you still treat routing as pure forwarding, you’re effectively trying to govern a “thinking, acting” system with the abstraction of a transparent proxy.
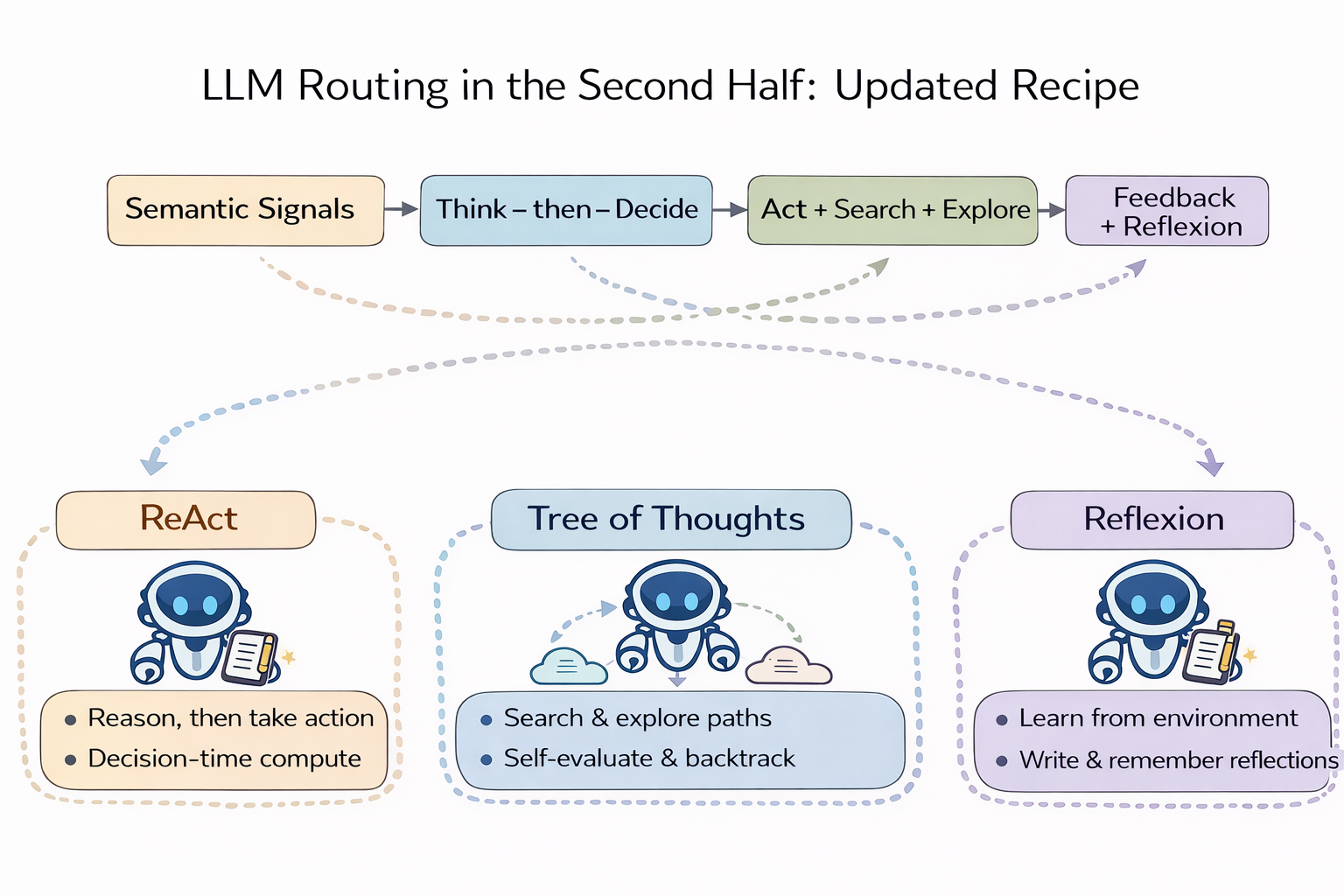
So the second-half recipe must upgrade:
Make decisions more deliberative — and let the system become more reliable through feedback from the environment.
Routing needs Reasoning + Acting
The core of ReAct isn’t “write a longer chain-of-thought.” It’s interleaving reasoning and actions: reasoning helps planning, error correction, and policy updates; actions connect the system to the environment to obtain observations — reducing hallucinations and improving interpretability.
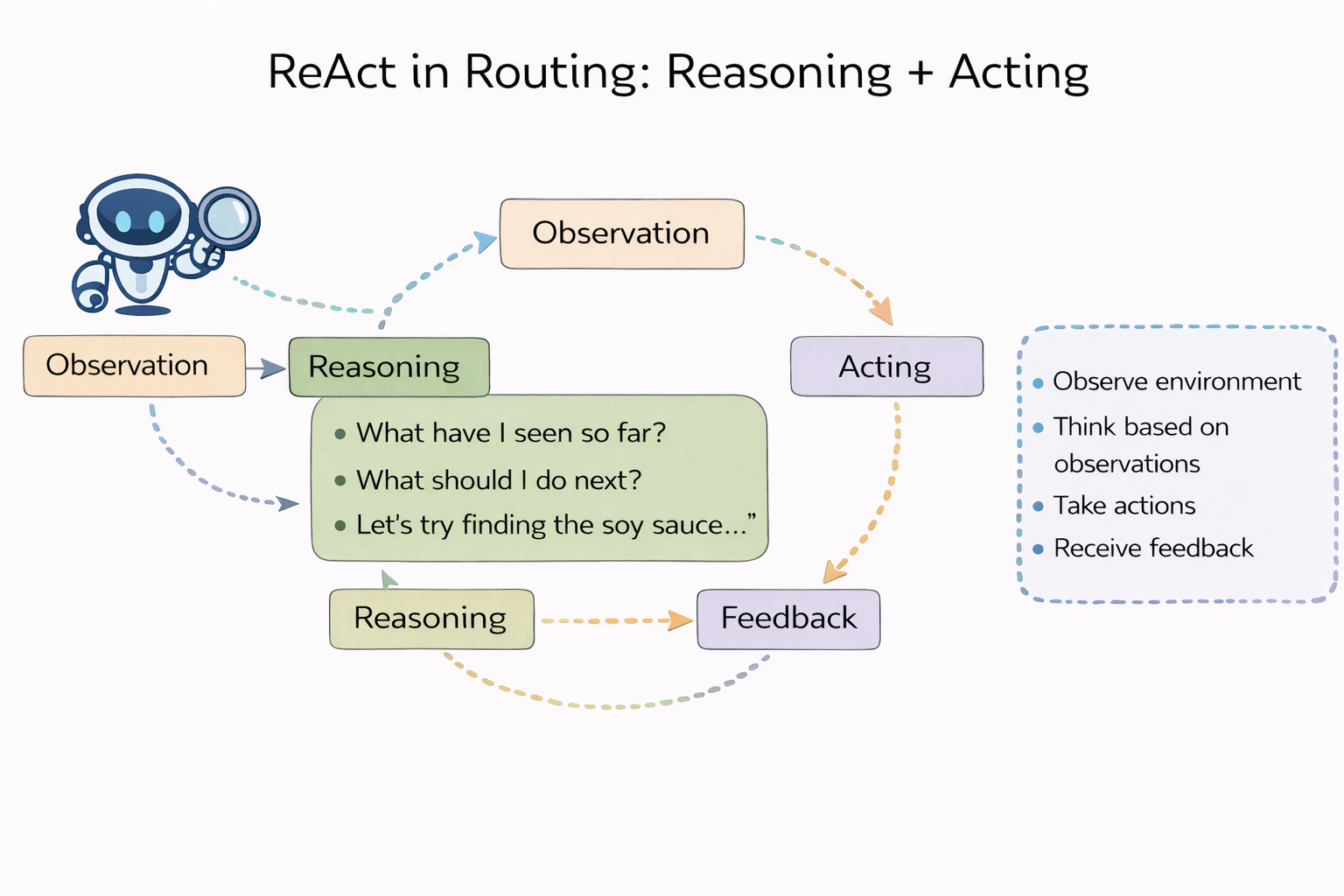
Bring this into routing and you get a direct conclusion: routing shouldn’t just make decisions based on static signals. Routing should also think first, act, then decide. It needs intelligence.
The “actions” can be concrete: retrieve first, run a verifier first, have an SLM clarify intent first, run safety checks on high-risk spans first, do a lightweight probe (e.g., use a cheap model to test uncertainty), and only then decide whether to escalate to a stronger model.
In other words, second-half routing is not just a traffic router.
It is an agent brain doing decision-time compute.
Routing needs search, backtracking, and self-evaluation
Tree of Thoughts (ToT) says: standard LM inference is a left-to-right greedy process at the token level, but complex tasks require exploration, foresight, and backtracking. So ToT treats “thinking” as searchable intermediate states: expand multiple paths, self-evaluate, and roll back when needed.
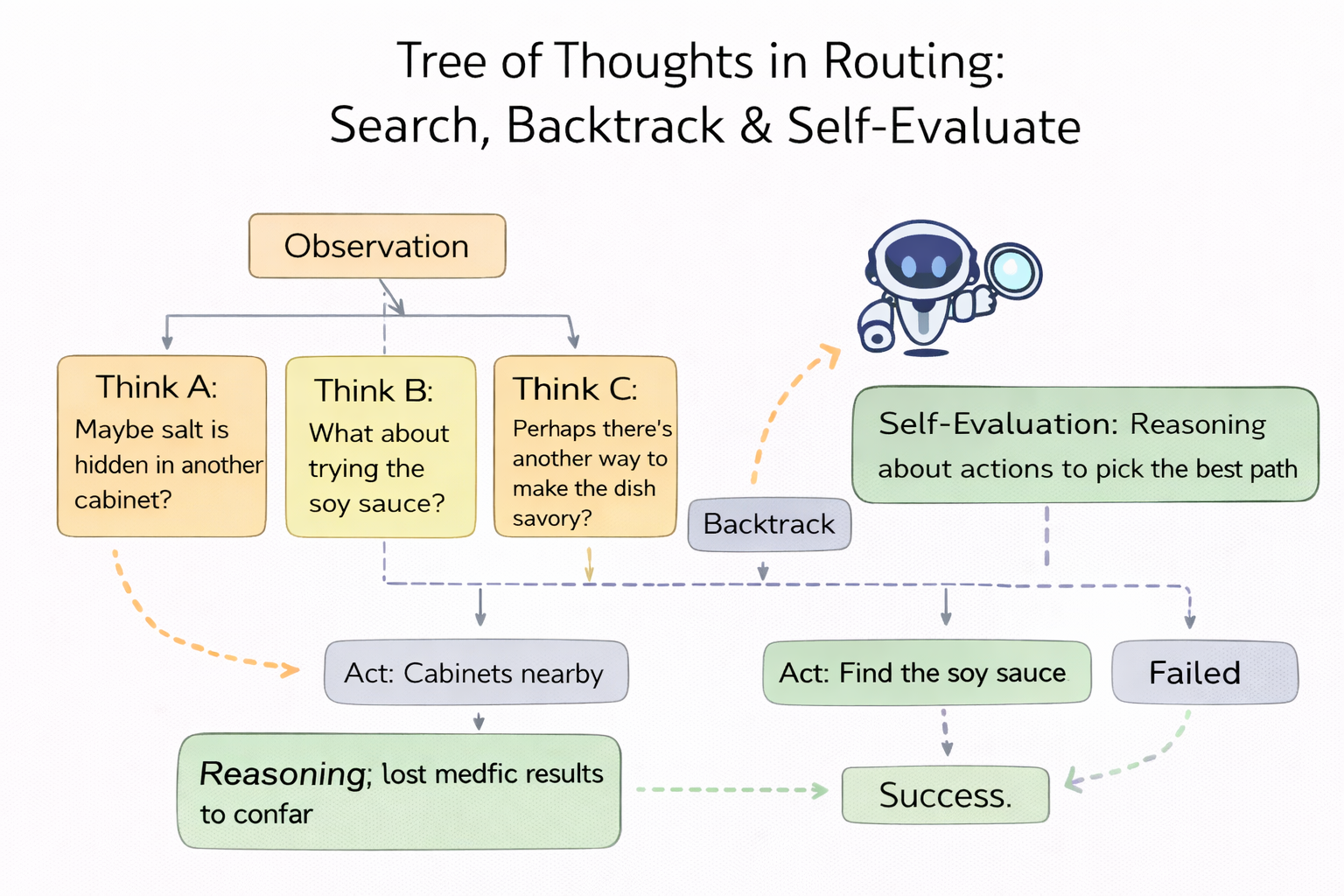
Bring that into routing and you end up redefining what “a route” even is: routing isn’t an if-else or a one-shot classification. It’s an explorable “strategy tree” — different paths correspond to different capability bundles (model / reasoning mode / tools / verification / caching / audit).
For the same request, you might expand multiple candidate paths:
- Path A: SLM direct answer (fast, cheap, risky)
- Path B: mid model + retrieval (steady, higher cost)
- Path C: strong reasoning model + verifier (most reliable, most expensive)
- Path D: clarify first, then answer (push uncertainty to the user)
The ToT lesson is: don’t pretend you can one-shot it. Allow the routing layer to do bounded search, using self-evals and external observations to choose next steps — and backtrack when necessary. Routing shifts from “splitting traffic” to “planning.”
Routing needs feedback and reflexion
Reflexion goes one step further: it decouples “getting stronger from mistakes” from weight updates. You don’t necessarily need to fine-tune. The system can turn task feedback into language-based reflection, write it into episodic memory, and make future decisions better.
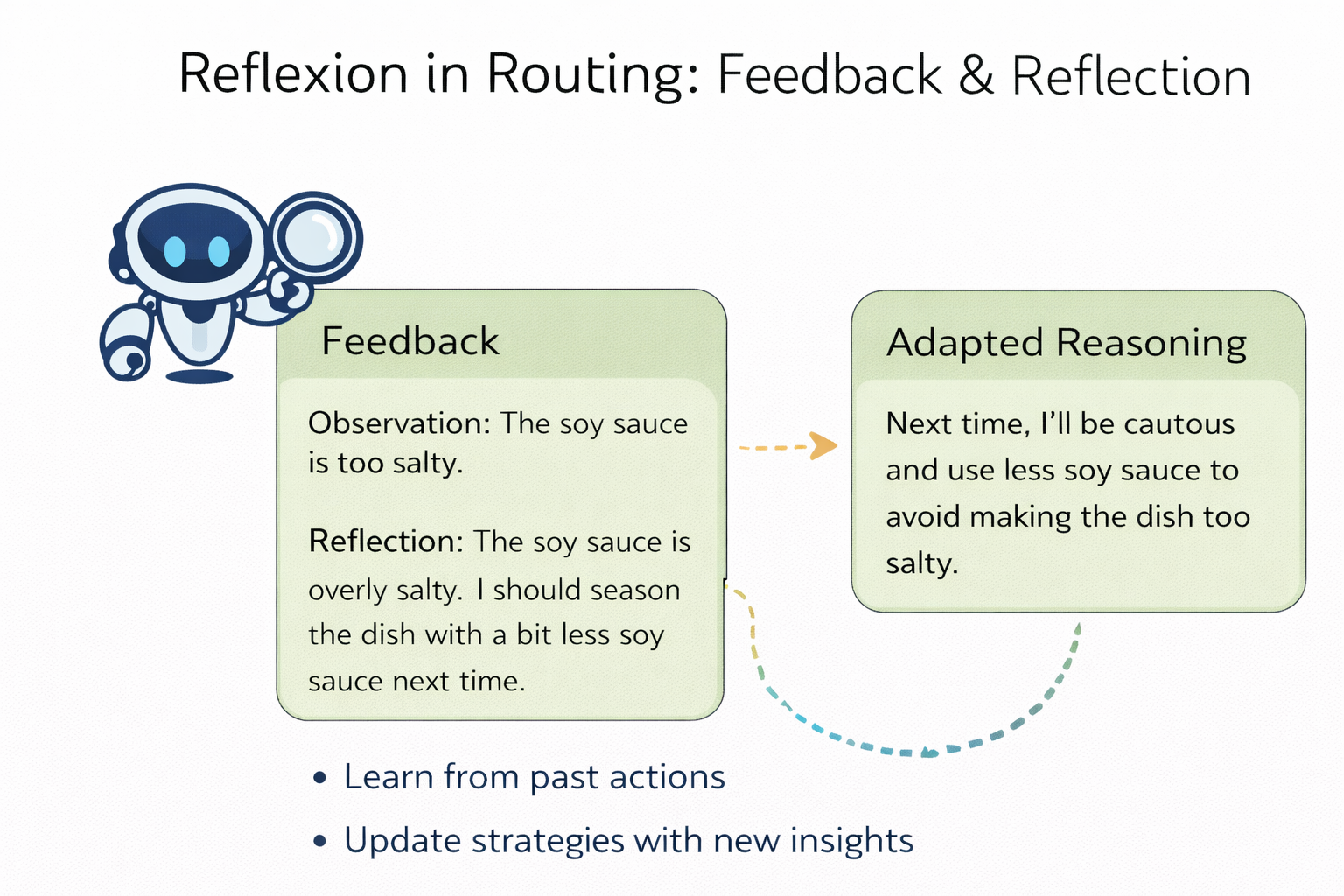
Bring that into routing and you get the most critical step of the second half: the routing system must be reflexive. Otherwise it will keep repeating the same class of errors.
And feedback sources can be painfully real: positive/negative user feedback, whether the task was resolved in one pass, tool-call failures, factuality checks, KV-cache hit rates, whether a policy caused complaints or compliance incidents… These aren’t “training data,” but they are the most valuable online signals a system can get.
So the second-half recipe becomes clearer:
- The first half: “unified entry + token governance + reliability + pluginization + observability.”
- The second half must add: “semantic signals + think-then-decide + tree search + feedback/reflexion.”
That’s the bridge: homogenization isn’t bad — it means the infrastructure layer is getting solved. Real incremental innovation must move to a new abstraction layer:
move reasoning / acting / searching / reflexion up into the routing layer.
There’s an even deeper driver: collective intelligence
There’s also a more “anthropological” driver:
Human intelligence has never been just solo brilliance — it’s a composition of collective intelligence.
Teams have a measurable “collective intelligence factor” that explains performance across tasks, beyond just the maximum or average individual IQ.
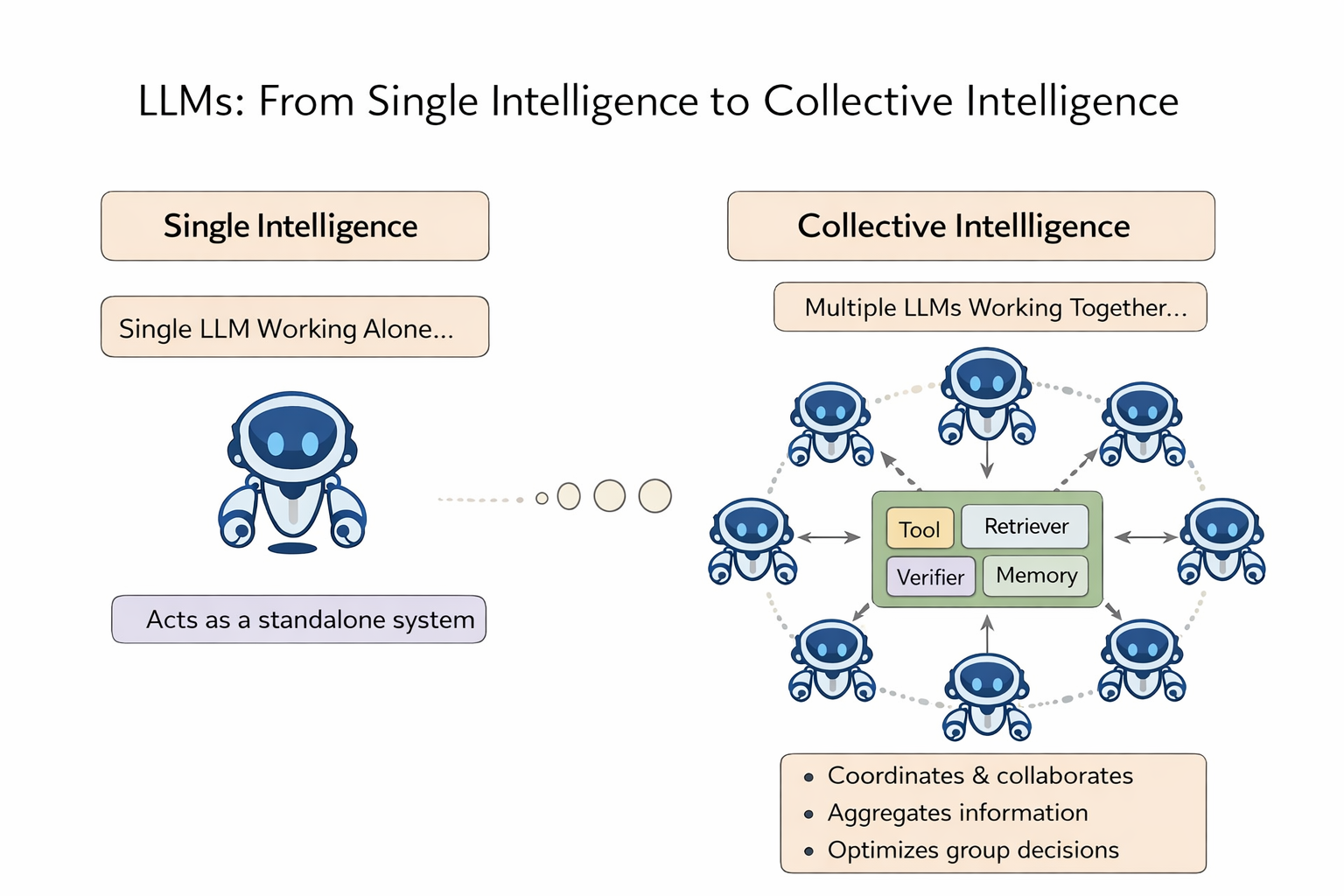
MIT’s Center for Collective Intelligence even frames its core question as: how can people and machines be connected so they can “collectively act more intelligently,” i.e., build “superminds.”
Bring that lens into LLM systems and you get a natural analogy:
LLMs are moving from “one big model fighting alone” to “a collective system of multiple models + tools + verifiers + memory.”
Routing should be the organizing mechanism of that collective intelligence.
If you treat SLMs, LLMs, reasoning models, verifiers, retrievers, and tool executors as different “experts,” then the second-half routing task is no longer “pick an endpoint.” It becomes the classic collective-intelligence problem: diversity, independence, decentralization, and aggregation — letting the system collaborate without groupthink, and aggregating results into a useful delivery for the user.
That’s why I say second-half routing is more like a “brain.” It’s not just dispatching traffic — it’s organizing an intelligent group.
The second half
The core change of the second half can be summarized in one sentence:
the object of routing shifts from endpoints to behavior (system behavior).
You’re no longer just choosing “which model.” You’re choosing “how the system should behave”:
- Should we enable reasoning? At what intensity?
- Should we clarify first, then answer? Retrieve first, then reason?
- Should we run a verifier? Force citations? Enable stricter audit policies?
- If semantics drift across turns, should the strategy migrate accordingly?
- Is the failure cost high? Should we be conservative or aggressive?
If first-half routing is traffic control, second-half routing is closer to an Intelligence Control Plane: decisions driven by signals, constrained by policy, uncertainty reduced via search and actions, and continuously evolved through feedback and reflexion.
And this forces you to redo three things: Evaluation, Stateful, Learning. Because the moment you optimize for “best system behavior,” you’ll realize single-turn accuracy does not represent real-world utility.
Thesis: System Intelligence
The next stage is system intelligence: pushing intelligence up to the system level.
Under a mixture-of-models (SLM + LLM) architecture across edge + cloud, users shouldn’t need to care which model got called — the experience should feel more like “Auto”: the system chooses the capability path.
There are three directions. But they’re not three feature cards — they are three parts of a closed loop: decision, collaboration, governance.
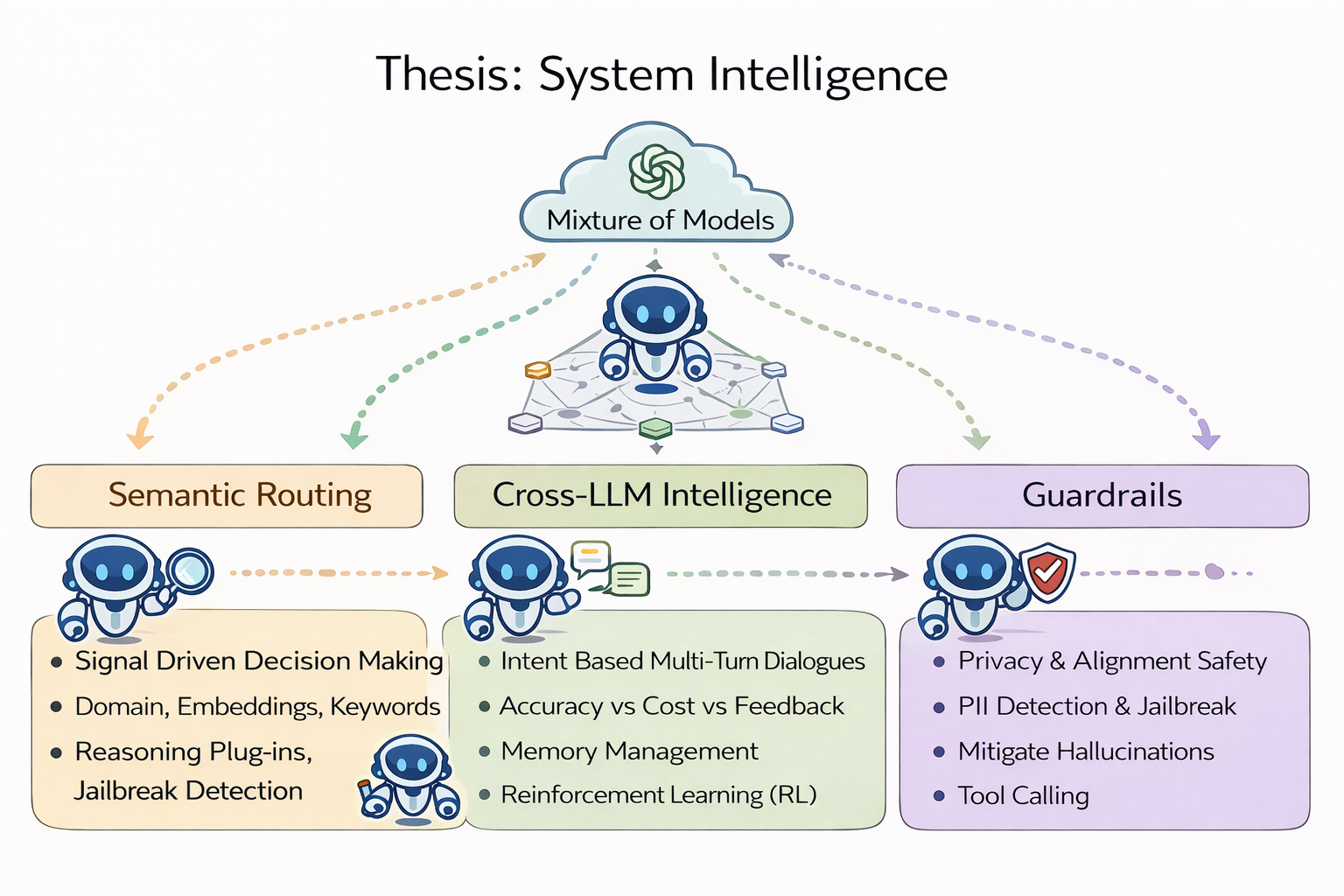
1) Semantic Routing: signal-driven decision
Capture higher-value signals — the semantic signals we used to ignore.
- In the first half, signals mostly came from system state: load, health, cost.
- In the second half, signals must come from semantics and task state: domain, intent, uncertainty, risk level, factuality cues, user-feedback trajectories, hidden attack graphs inside conversations, etc.
More importantly: these signals shouldn’t just be used to “stamp a label.” They should feed into a Think-then-Decide loop: reason about what we’re missing and what we’re uncertain about, act to fill the gaps, then make the final decision (a routing-native version of ReAct).
2) Cross-LLM Intelligence: make the experts collaborate
If you view the system as collective intelligence, Cross-LLM is not “pick one” — it’s “divide work + aggregate.”
Different models vary wildly across tasks. Different verifiers, retrievers, and tool executors each excel at different subtasks. The second half is about enabling them to collaborate with minimal coordination overhead, while preserving independence to avoid error amplification through resonance (the classic failure mode of group systems).
- ToT gives a direct playbook: treat “what to do next” as a tree search, choose paths using self-evaluation and external feedback, backtrack when needed.
- Reflexion provides another axis: write failures into reusable reflective memory as a prior for future aggregation and scheduling — the system becomes more and more like a real team as it runs.
3) Guardrails: governance is not an add-on — it’s the “team norm” of collective intelligence
Once you build a collective system, the role of guardrails changes:
It’s not just blocking dangerous content. It’s closer to organizational: permissions, audits, norms — who can do what; which scenarios must escalate to stricter paths; which actions require double checks (verifiers); which information must cite sources; which failures require mandatory postmortems written into reflective memory.
In multi-turn conversations, attackers can decompose harmful intent into multiple harmless-looking prompts, gradually steering toward the target through a dialogue graph. Second-half guardrails must have session-level state and graph-level evidence, otherwise single-turn scanning is trivially bypassed.
Where it lives
System intelligence can live in three places — more like three product lines:
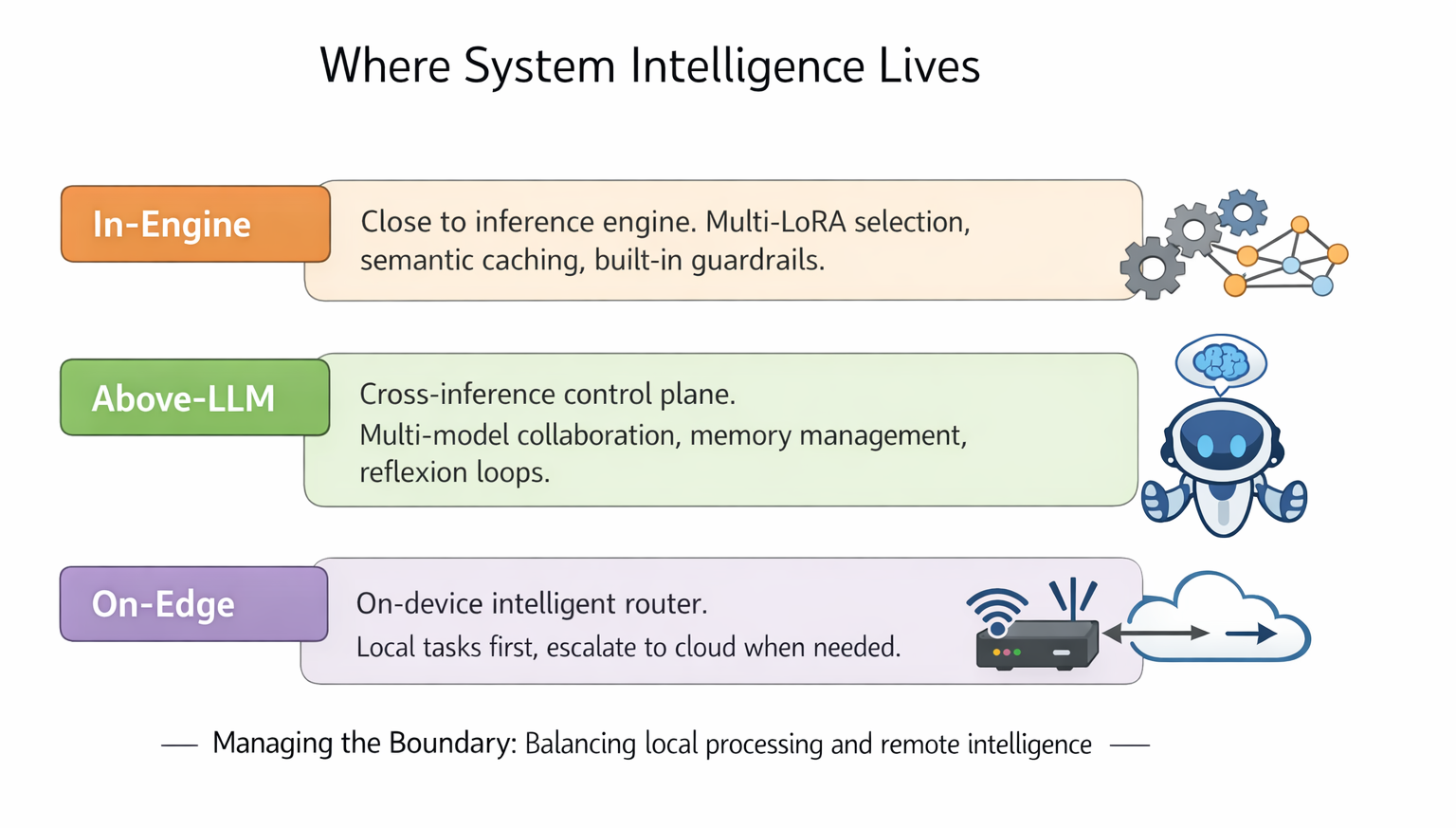
- In-engine: closer to inference engine. Good for multi-LoRA auto-selection, cross-instance semantic caching/stateful communication, and low-latency built-in guardrails.
- Above-LLM: a cross inference engine / external-provider control plane. Good for multi-model collaboration, memory management, policy search, and reflexion loops. It looks like an agent, but I prefer to call it the “brain above LLMs”: organizing collective intelligence.
- On-edge: a local-first product line. Put a lightweight intelligent router + SLM on-device to handle privacy-sensitive and high-frequency requests with near-zero marginal cost. When uncertainty, task difficulty, or policy requires more capability, the router escalates to remote LLM providers.
Routing becomes not only a control plane for cloud models, but also a boundary manager between local and remote intelligence — optimizing quality/cost and data exposure, connectivity, and energy.
Evaluation Matters
As models multiply and routing gets smarter, we can almost predict what happens next: more and more LLM routers —
open-source, commercial, cloud-native, bundled with inference engines.

The hard question is: how do we evaluate an intelligent router?
For traditional gateways, evaluation is straightforward: latency, throughput, SLA, error rate, cost.
But second-half routing doesn’t just pick an endpoint; it picks behavior: when to reason, when to retrieve, when to clarify, when to refuse, when to escalate to heavier paths.
So evaluation must upgrade:
What dimensions should define “good system intelligence”? Task completion rate? Multi-turn efficiency? Stability and consistency? Risk and compliance? The Pareto frontier of cost vs quality? Or whether the system becomes more reliable under long-term feedback?

Interestingly, we’re already seeing early “evaluation systems” emerge — for example, RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers: a public platform/leaderboard that puts routers under the same dataset, difficulty tiers, and metrics — and supports automated updates.
At minimum, it signals one thing: routing intelligence must be measurable. Otherwise it’s a castle in the air — and the narrative will quickly shift from “what features do you have” to “how good are you under the same constraints.”
This will take real effort and real resources.
In the End
Looking back at the first-half game:
- We turned LLMs into callable, governable, scalable services.
- We converged on unified entry, token governance, reliability, and inference scheduling.
- Homogenization arrived; the recipe started crushing incremental innovation.
The second-half game should be:
- Admit the backend has changed: it’s uncertain, and it can lie.
- Move reasoning + acting into routing decisions: think first, act, then decide.
- Move search and backtracking into routing search: deliberate over a strategy tree, not one-shot classification.
- Move feedback and reflexion into the routing loop: without changing weights, become more reliable through memory and reflection.
- Upgrade from solo intelligence to collective intelligence: make multiple models, tools, and verifiers collaborate like a team — and routing is the team’s organizing mechanism.
- In the first half, routing transports requests.
- In the second half, routing builds collective intelligence.
Welcome to the second half of LLM routing!
Acknowledgements
This blog post is inspired by The Second Half by Shunyu Yao.