
Six months ago, I wrote The Second Half of LLM Routing. At the time, my argument was that LLM routing was reaching a turning point. The first half of routing made models look like manageable backend services: unified API entry points, token quotas, retries, fallbacks, observability, load balancing, and cost controls.
That work mattered because it made AI production systems possible.
But it also started to converge. Once every AI gateway begins to look like the same recipe, the next question is no longer how to forward requests more reliably. The question becomes what “routing” should mean when the backend is no longer a deterministic service, but a model that can reason, act, call tools, fail in subtle ways, and change behavior through feedback.
Back then, I described the second half this way:
In the first half, routing transports requests. In the second half, routing builds collective intelligence.
I still believe that, but after another half year of watching enterprise AI adoption, open source inference, model releases, agentic coding, and infrastructure teams trying to control real token bills, I would say it more directly.
The second half of routing is not only the move from endpoint selection to behavior control. It is about intelligence resource allocation: deciding how much intelligence each piece of semantic work deserves, where that intelligence should run, and what cost, latency, privacy exposure, hardware capacity, and energy footprint the system is allowed to spend.
That is why semantic routing now feels less like an API gateway problem and more like energy infrastructure.
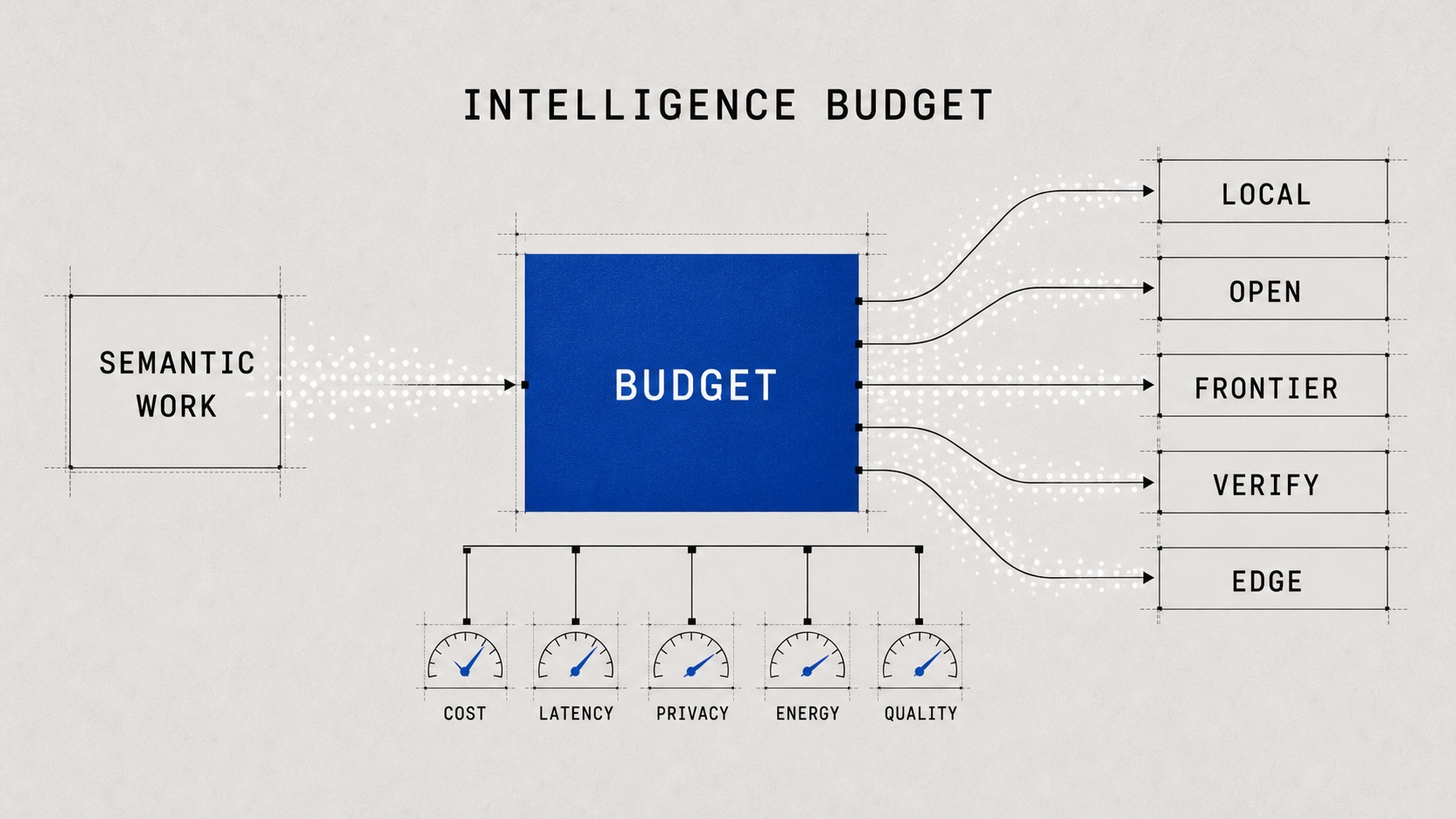
1. The Bill Arrives Before the Architecture
Every computing era begins by making a scarce resource feel abundant.
The industrial age made mechanical force portable. The cloud era made compute elastic. The AI era has made something stranger callable: intelligence, exposed through APIs, metered by tokens, and inserted into millions of workflows.
The first visible effect is acceleration. A frontier model makes a product feel smarter. An agentic coding tool changes how developers work. A support assistant compresses repetitive labor. The new resource looks flexible, almost liquid.
Then the bill arrives, and the architecture becomes visible.
Salesforce: Token Spend Becomes Architecture
In May 2026, Business Insider reported that Salesforce CEO Marc Benioff said the company could spend around $300 million this year on Anthropic tokens. The number is eye-catching, but the architecture question behind it matters more.
Benioff pointed toward an intermediary layer that decides which inputs deserve a frontier model and which can be handled by smaller models. That is the moment model choice stops feeling like a developer preference and starts becoming infrastructure strategy.
Microsoft: Tool Choice Becomes Control
Around the same time, The Verge reported that Microsoft was preparing to wind down many Claude Code licenses internally and move more developers toward GitHub Copilot CLI. The point is not a verdict on Claude Code; the report described it as popular inside Microsoft. The point is that popularity did not settle the architecture.
At enterprise scale, an AI coding tool is also a security boundary, a developer workflow, a cost center, and a platform surface. That is not per-request semantic routing, but it is the same discipline: raw capability is only one variable; control of the decision layer starts to matter just as much.
Red Hat: Hybrid AI Needs Routing
Red Hat framed a related tension as the “agentic paradox”: frontier models are often the fastest path to agentic adoption, but routing every agentic workload to them becomes difficult to sustain at enterprise scale because of cost, latency, confidentiality, sovereignty, and control.
NVIDIA: The Supply Side Gets Faster
There is also a supply-side version of the same pressure. NVIDIA recently described AI data centers as token factories, arguing that AI efficiency and revenue scale through better performance per watt. That is exactly what frontier hardware and inference engine teams are trying to do: squeeze more useful tokens out of every watt of power and every dollar of infrastructure.
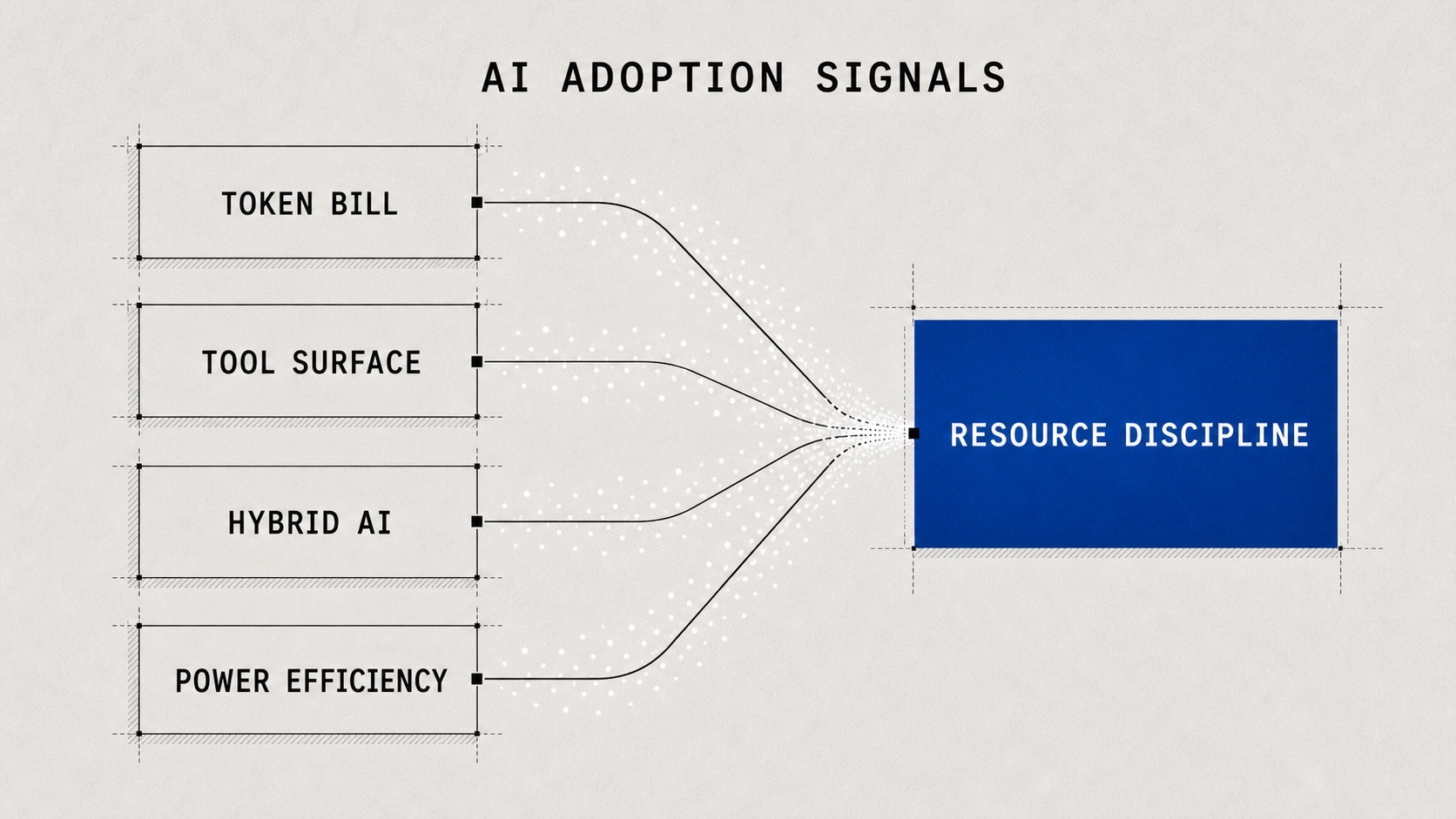
These stories are not identical. One is about token bills. One is about the cost and governability of AI tool surfaces. One is about hybrid AI. One is about performance per watt. But together they show the same transition:
AI is moving from capability discovery to resource discipline.
The supply side will keep improving tokens per watt per dollar. The demand side now needs to decide which semantic work deserves those tokens in the first place. A faster token factory still wastes power if every workload is sent through the most expensive lane.
Frontier models remain the fastest way to discover new capabilities, but they are not, by themselves, the architecture of scale.
2. Tokens Are Not the Unit
The industry likes tokens because tokens are easy to count. They are convenient for billing, quotas, and dashboards. They turn something messy, language, into something finance and infrastructure teams can track.
But tokens are a billing unit, not a value unit.
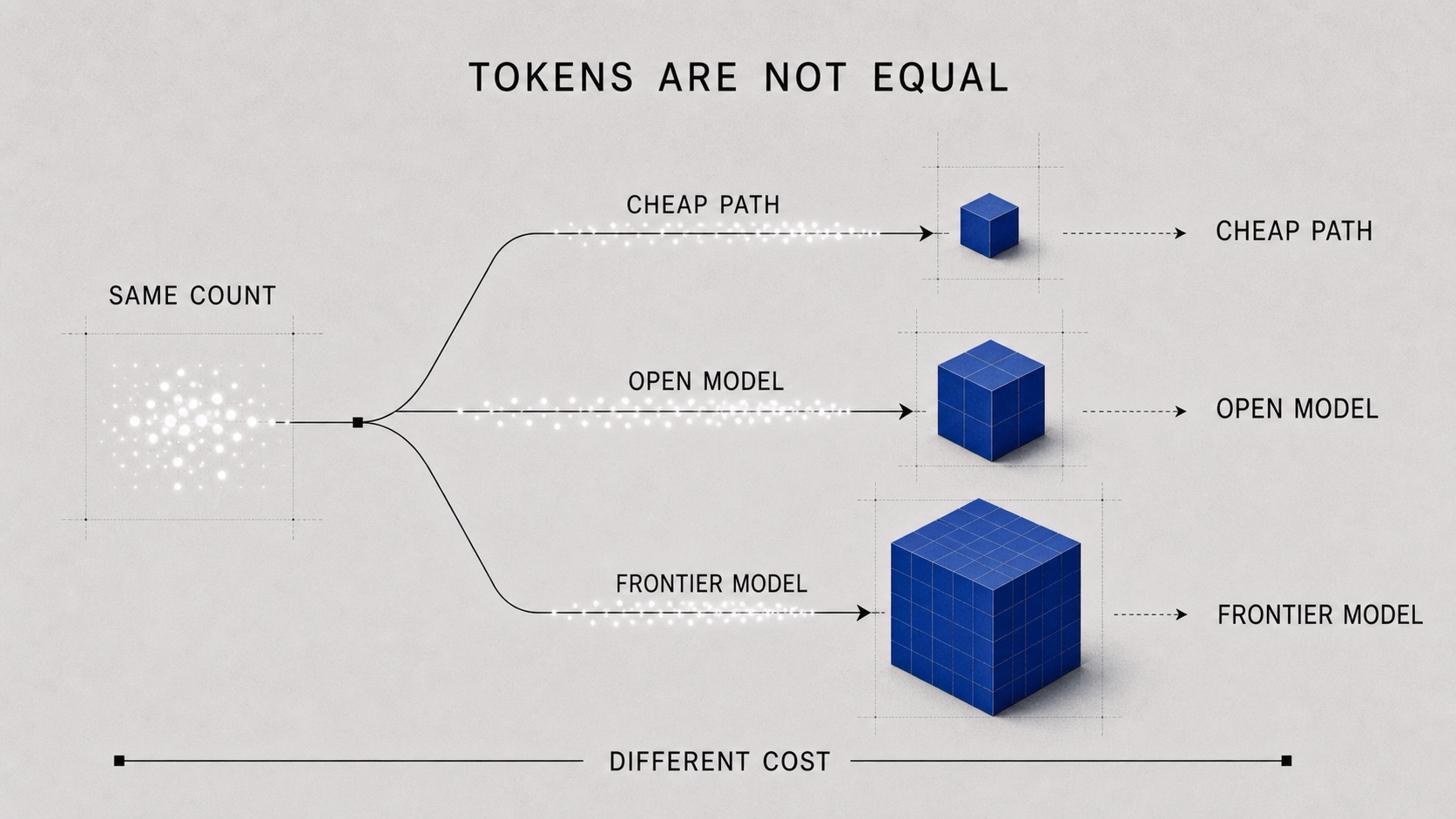
The same token count can pass through a small local model, a specialized open model, a frontier closed model, a reasoning model, or a model running on an edge device. The bill, latency, energy footprint, privacy risk, and intelligence density are all different.
Counting tokens is like counting kilowatt-hours without asking what the electricity powered. One kilowatt-hour used to keep a hospital operating and one kilowatt-hour wasted by an idle machine share the same unit, not the same value. AI systems have the same problem.
One token may be cheap autocomplete. Another may be the deciding step in a high-risk reasoning chain. One request may be a low-stakes formatting task. Another may require retrieval, verification, policy checks, and a stronger model because the failure cost is high.
So the real question is not:
How many tokens did we use?
The real question is:
Did we spend the right kind of intelligence in the right place?
That is a different kind of accounting. It asks the system to understand the semantic workload before spending compute. Is the task simple or ambiguous? Private or public? Reversible or dangerous? Latency-sensitive or quality-sensitive? Cheap enough to answer locally, or important enough to escalate?
This is where token economics becomes system design.
3. Frontier-by-Default Is a Temporary Architecture
The simplest AI architecture is always:
Send everything to the strongest model.
It is easy to build. It is easy to explain. It gives good demos. It minimizes engineering effort in the short term because the model absorbs complexity that the system does not know how to model yet.
In the early stage of adoption, that is rational.
When a team is trying to prove AI works, frontier-by-default is often the fastest path. It reduces product risk. It gives users a better first experience. It lets teams focus on workflow and adoption instead of building a routing layer too early.
But architecture that works for discovery often breaks at scale.
When every workflow becomes AI-assisted, when agents run continuously, when coding tools expand across thousands of developers, when customer support, sales, analytics, compliance, and internal operations all begin to consume model calls, the question changes.
The company no longer asks:
Can AI do this?
It asks:
Can we afford this, control this, govern this, and scale this?
That is when frontier-by-default starts to look less like an architecture and more like a subsidy paid by the early phase of adoption.
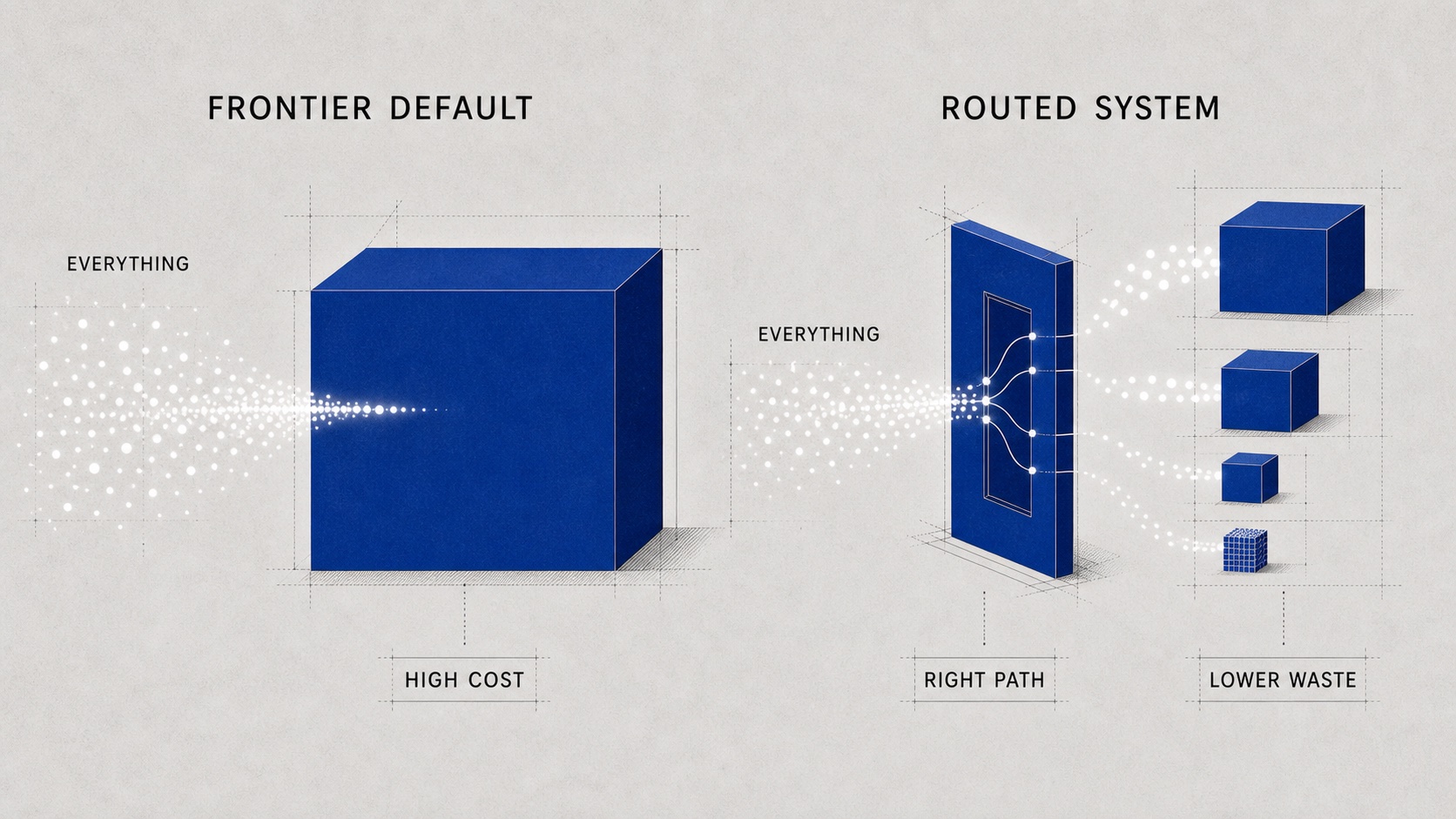
The future is not one frontier model serving every request. The future is a heterogeneous fabric of intelligence:
- frontier closed models for high-value reasoning and hard escalation paths
- open-weight models for controllable, private, and cost-efficient workloads
- small models for classification, extraction, intent detection, routing, and frequent low-risk tasks
- domain models for specialized knowledge and enterprise context
- verifiers for checking claims, actions, policies, and citations
- retrieval systems and memory layers for grounding
- edge models for local privacy, low latency, and near-zero marginal cost
- different generations of hardware that still need to be used efficiently
This is not anti-frontier. It is what mature infrastructure does: preserve the most capable resource for the places where it actually changes the outcome.
Electric grids do not route every load through the most expensive power source. Networks do not send every packet through the same path. Cloud platforms do not run every job on the largest instance type.
Mature systems differentiate demand, and AI systems will have to do the same.
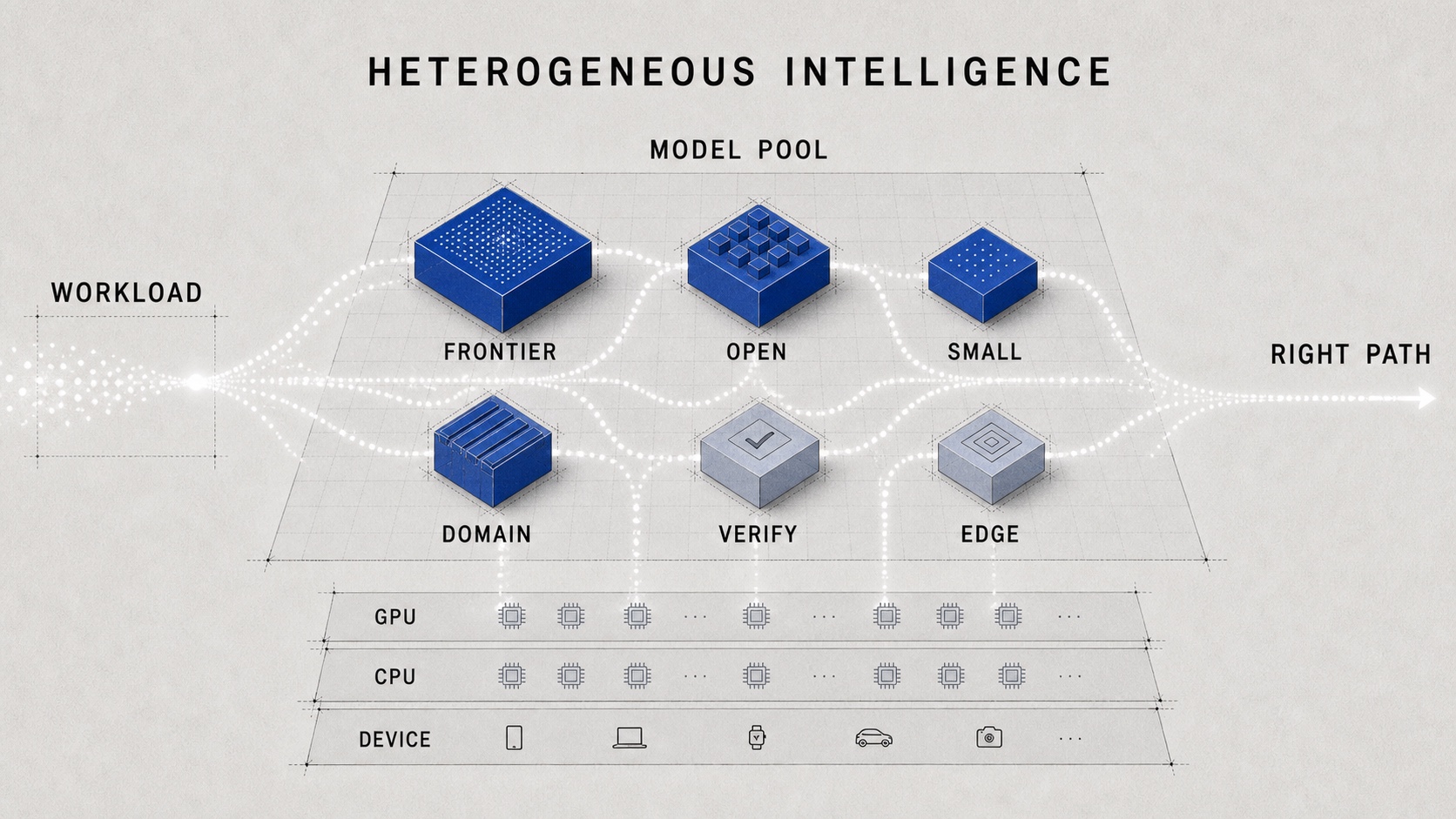
4. Hybrid AI Is Not Just a Deployment Topology
If frontier-by-default is the temporary architecture, hybrid AI is what comes after.
But hybrid AI is not a slide with one cloud model, one private model, one open model, and one edge model. That is inventory. Architecture starts when the system can decide what each piece of work actually deserves.
The architecture question is sharper:
Who decides where semantic work should go?
A hybrid system without routing is just more endpoints. It may lower cost in obvious cases, but it cannot reason about the tradeoff between quality, latency, privacy, risk, and energy. The missing piece is a control layer that turns workload signals into capability paths.
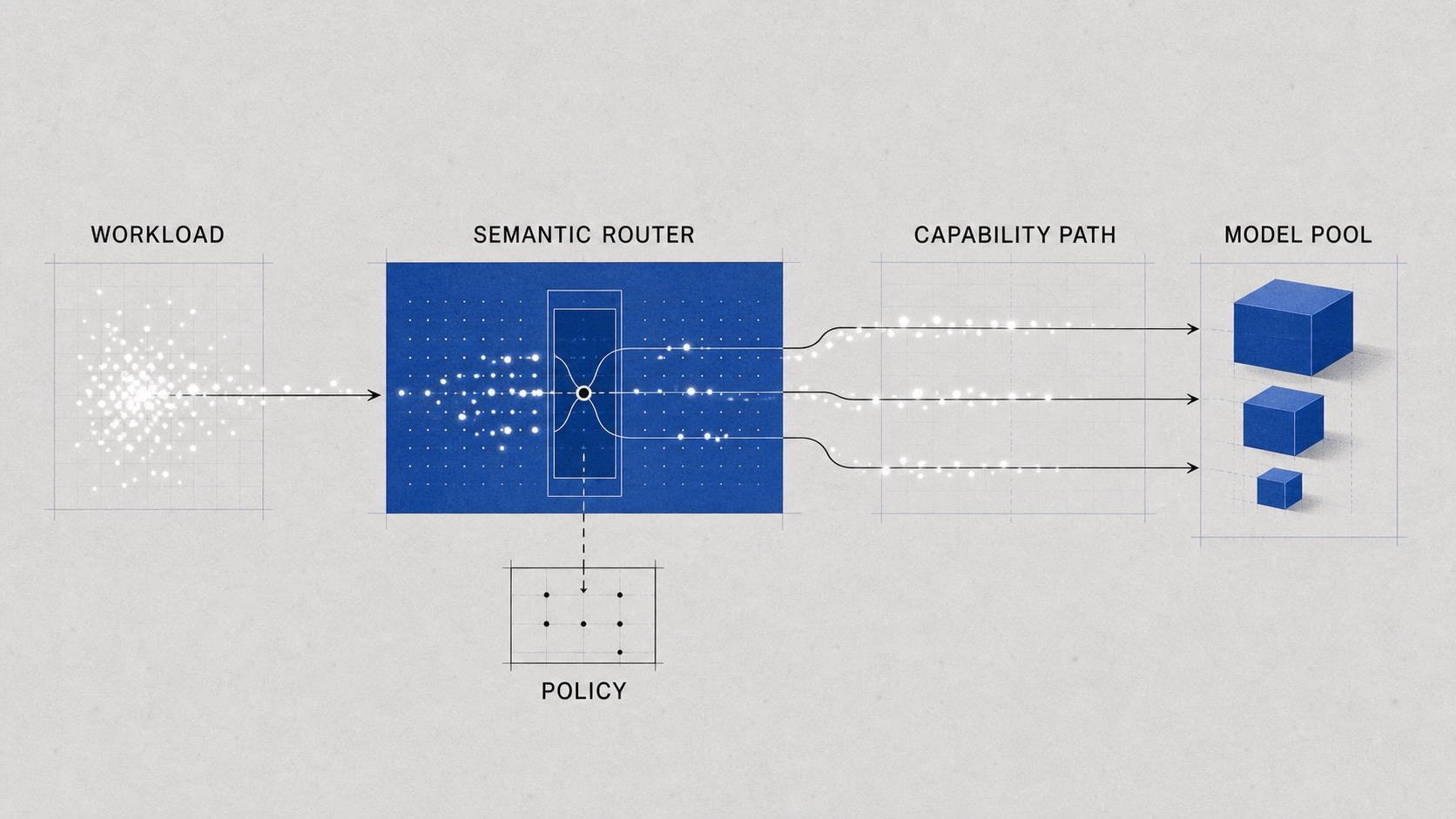
A path may be:
- answer directly with a small model
- retrieve first, then answer with a mid-size model
- classify risk, then apply a stricter policy
- ask a clarification question before spending expensive reasoning
- run a verifier before returning the answer
- escalate to a frontier model only when uncertainty or failure cost justifies it
- keep the task on-device because privacy matters more than marginal quality
This is why “the right model for every request” is a useful slogan but not the whole idea. The real unit of architecture is not always a model; it is a capability path.
5. Semantic Routing as Energy Infrastructure
At small scale, model choice feels like a quality decision. At infrastructure scale, it becomes an allocation problem, which is why I keep coming back to energy.
Energy here is not a decorative metaphor. I do not mean semantic routing is the power grid; I mean intelligence is now a metered, energy-consuming resource, and the system needs a way to decide when spending it is justified.
The wrong lesson is “use cheaper models.” Cheap-by-default is the mirror image of frontier-by-default. Both avoid judgment.
The real point is to budget intelligence. A small model may be enough for routine work. An open model may be right when control and cost matter. A frontier model is still worth it when reasoning depth or failure cost justifies the bill. Sometimes a verifier beats another generation step. Sometimes retrieval beats reasoning. Sometimes asking one clarifying question is the most efficient path.
In the old internet, routing moved packets. In AI systems, the traffic is semantic work: intent, uncertainty, context, memory, privacy risk, tool use, and action. Once traffic carries meaning, routing stops being thin forwarding and becomes allocation.
For me, this is the first-principles reason semantic routing matters: it treats intelligence as a resource to schedule, not a magic endpoint to call.
The industry is already attacking the supply side. Hardware teams and inference engine teams are doing exactly what they should do: maximize tokens per watt per dollar.
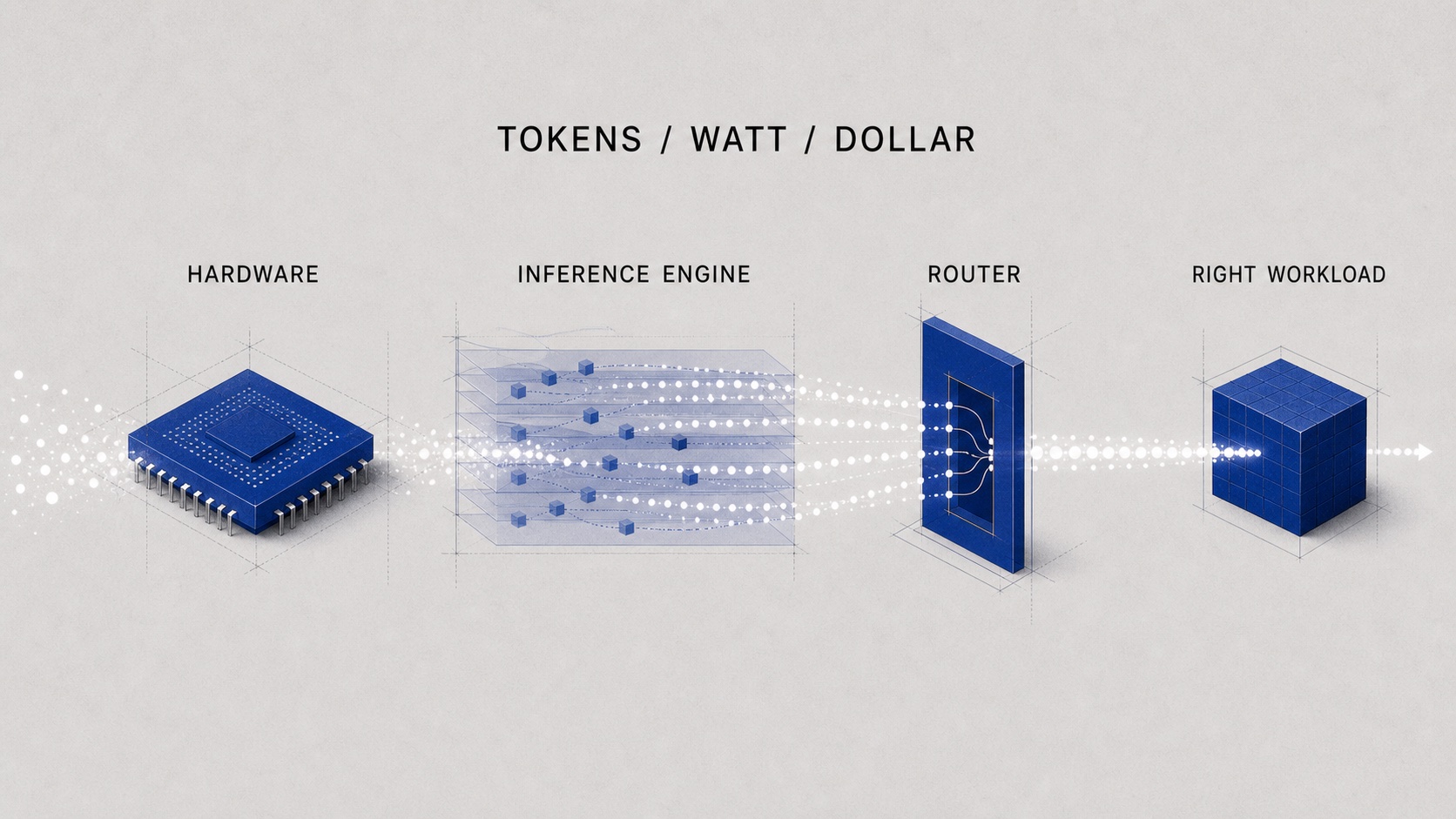
Better accelerators, better kernels, better batching, better KV-cache systems, better speculative decoding, better serving engines, and better cluster scheduling all push in the same direction: more useful tokens from the same power envelope.
But supply-side efficiency is only half the problem. The other half is demand-side allocation.
If every semantic workload can consume the most expensive path, the system is powerful but wasteful. If every workload is forced onto the cheapest path, the system is efficient but dumb. The hard problem is knowing when each path is worth it.
That is what turns hybrid AI from a deployment pattern into an energy architecture.
6. The Layer We Are Missing
But an energy architecture cannot stop at the slogan level. If semantic routing is going to decide how intelligence is spent, the decision layer has to become something engineers can inspect, policy teams can constrain, and infrastructure teams can improve.
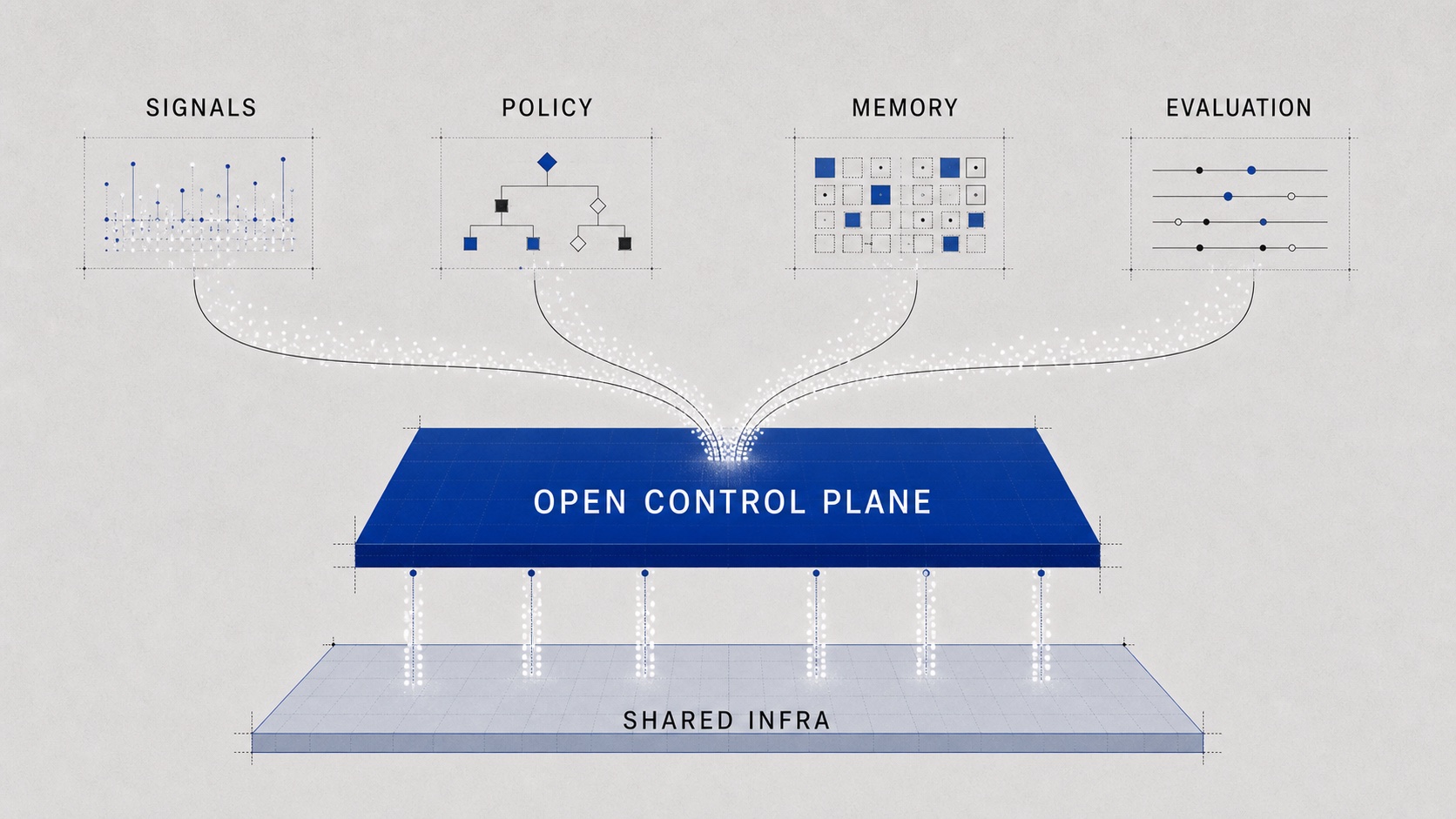
That is the missing layer: not another model endpoint, but the system primitives that make routing decisions expressible, observable, measurable, and compatible with the rest of the serving stack. I think it needs at least six pieces.
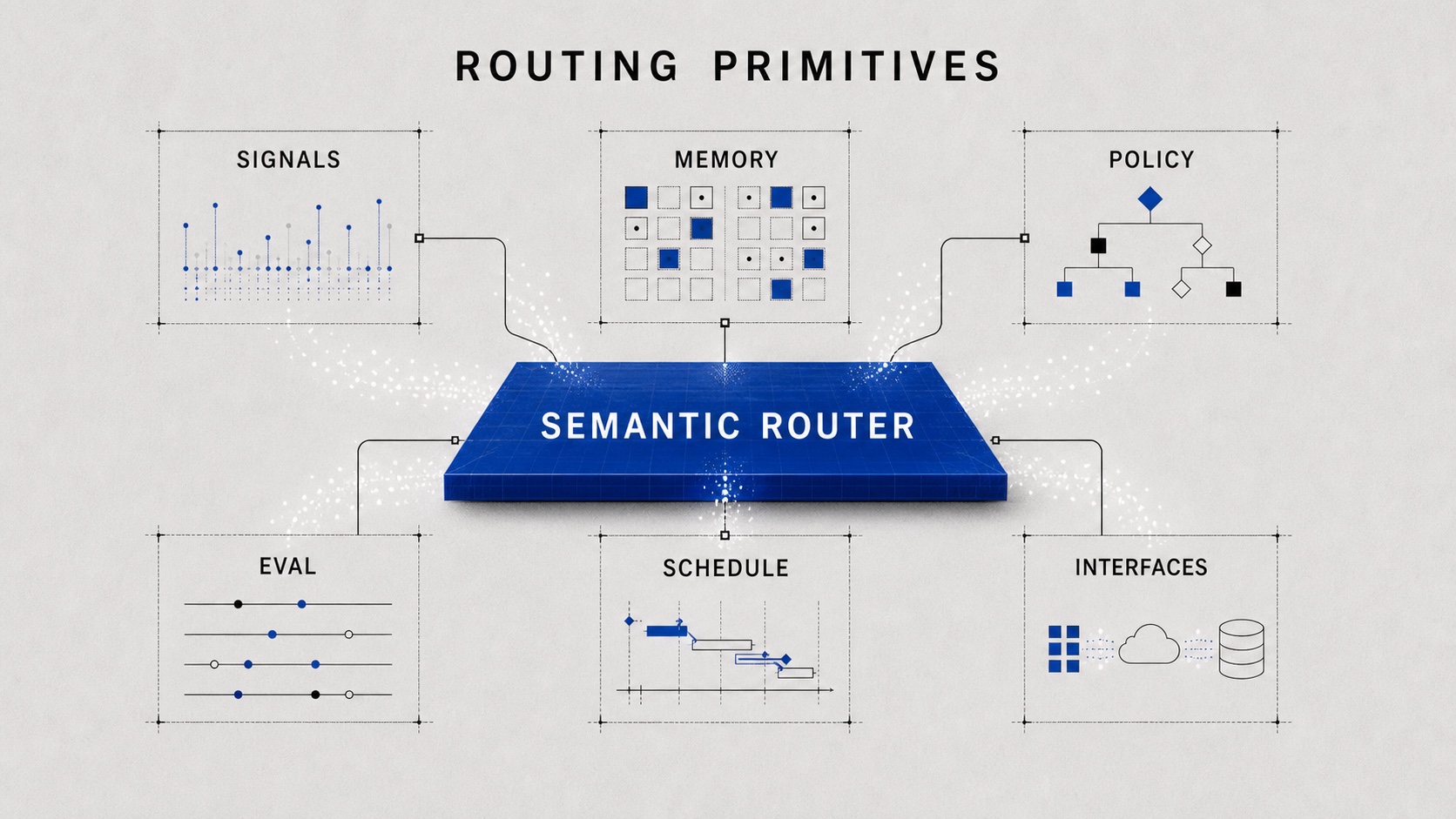
1. Workload signals.
The system has to understand more than prompt length and tenant ID. It needs signals for intent, domain, difficulty, uncertainty, privacy, safety, tool requirements, expected output type, failure cost, and historical behavior. Without workload signals, routing collapses back into static rules and cannot make intelligent allocation decisions.
2. Routing memory.
A router should not repeat the same decision blindly. It should remember which paths worked, which failed, which users or tasks require stricter handling, and which policies caused friction. Routing without memory cannot improve; it can only re-run yesterday’s assumptions.
3. Policy languages.
As routing becomes more powerful, organizations need a way to express constraints: what can run where, which data can leave the boundary, when a verifier is mandatory, when escalation is allowed, and how cost-quality tradeoffs should be handled. Natural language prompts are not enough for infrastructure policy.
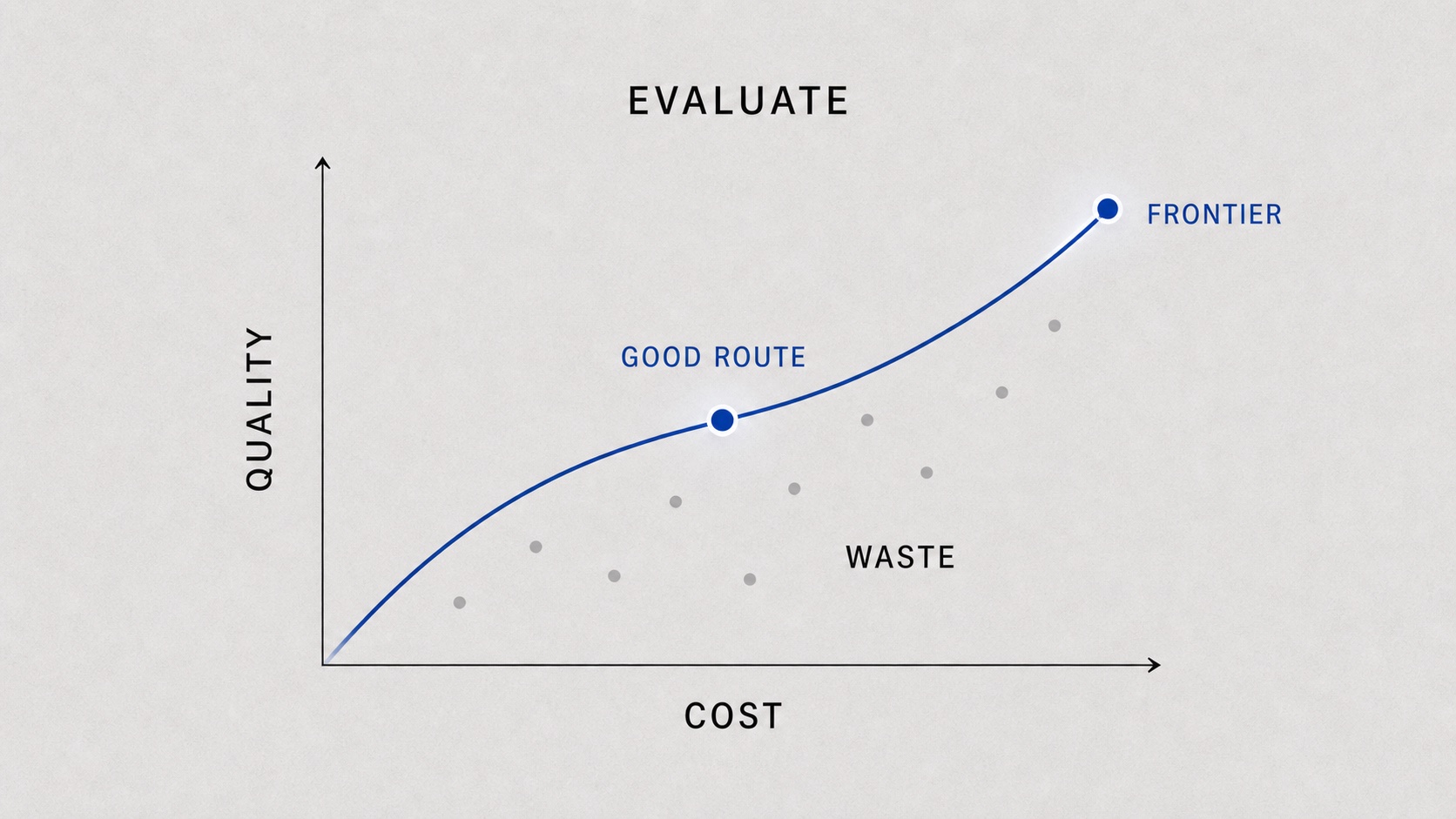
4. Evaluation.
If a router claims to be intelligent, it has to be measurable. Accuracy alone is not enough. We need cost-quality frontiers, task completion rates, latency distributions, privacy guarantees, safety outcomes, stability across multi-turn sessions, and evidence that the system improves through feedback. Otherwise “routing” becomes another hidden optimization with no accountable frontier.
5. System co-design.
I do not think this layer can be designed as an isolated policy box. The useful architecture is a co-designed loop: Workload -> Router -> Inference Pool. Workload signals shape routing decisions; routing decisions change batching, caching, queueing, model placement, KV-cache pressure, and hardware utilization; pool state should flow back into routing. A router that ignores the pool is incomplete, and an inference pool that ignores the workload is blind.
6. Transparent interfaces.
If this layer becomes important, it should be mostly invisible to applications and users. Product teams should not have to adopt a new serving surface just to benefit from better routing. OpenAI-compatible APIs, existing gateway protocols, and normal chat, completions, embeddings, and tool-calling semantics should keep working. The intelligence of the router should show up in better placement, policy, observability, and cost-quality behavior, not in a new API tax on the user.
That is where open source matters: not because every company will run the same router, or because one project should own the entire space, but because shared infrastructure needs shared language and shared contracts. It needs common workloads, common metrics, common failure cases, common policy concepts, and compatibility expectations, so routing can become infrastructure rather than a private product trick.
7. Why We Built vLLM Semantic Router
This is the problem space that led us to build vLLM Semantic Router.
The project started from a simple frustration: most routing layers could tell whether a backend was alive, busy, or cheap, but they knew very little about the work itself.
Early AI gateways made LLMs callable and manageable. That foundation is necessary. But once a system has multiple models, policies, risk levels, and deployment boundaries, routing has to answer a harder question:
Given this workload, this policy, this budget, this model pool, and this risk profile, what capability path should the system choose?
This is the part of Red Hat’s Technically Speaking conversation between Red Hat CTO Chris Wright and Steve Watt that matters to this argument. Their discussion around vLLM Semantic Router is not framed as another model-routing demo. It is about where enterprise AI needs control: which workloads can stay private, which policies decide the route, and how a broader accelerator landscape changes the economics underneath.
vLLM Semantic Router is one attempt to make that question concrete in open source. It is not the final answer, and it should not be. The field is still early: the right abstractions are being discovered, evaluation is immature, enterprises have different policies, models are changing quickly, hardware is changing more slowly, and edge, cloud, private deployment, and frontier APIs are evolving at different speeds.
That mismatch is exactly why routing matters. Models will keep improving, and hardware will keep improving, but mixed fleets do not automatically become intelligent systems. Someone still has to decide which request should touch which model, which data should cross which boundary, which accelerator should be used, and when the system should spend more reasoning instead of returning a cheaper answer.
There will be old GPUs, new GPUs, edge devices, private clusters, cloud APIs, open models, closed models, specialized models, verifiers, memory systems, and agentic tools all coexisting. The question is not whether one of them wins everything. The question is how to use all of them well.
The future of AI infrastructure is not one model. It is a system that knows how much intelligence each task deserves, and can explain the boundary it drew.
8. Before Power Becomes Tokens
My bet is simple: the next important AI infrastructure layer will sit before the token is generated. It will decide whether a piece of work deserves frontier reasoning, open-model inference, local compute, retrieval, verification, or no compute yet.
That layer is semantic routing.
In the cloud era, resource allocation was mostly deterministic. You asked for a machine, a container, or a node with a known shape: 1C / 2G, a memory limit, a CPU quota, a namespace, a cgroup. The boundary was explicit. The system could isolate it, meter it, schedule it, and enforce it.
AI changes the allocation primitive. The request is often a prompt, but the prompt carries more than text. It carries intent, uncertainty, context, risk, privacy, expected quality, and failure cost. In the cloud era, users asked for resources by declaring a shape. In the AI era, they increasingly ask for resources by describing a goal. The boundary is no longer only CPU and memory. The boundary is semantic.
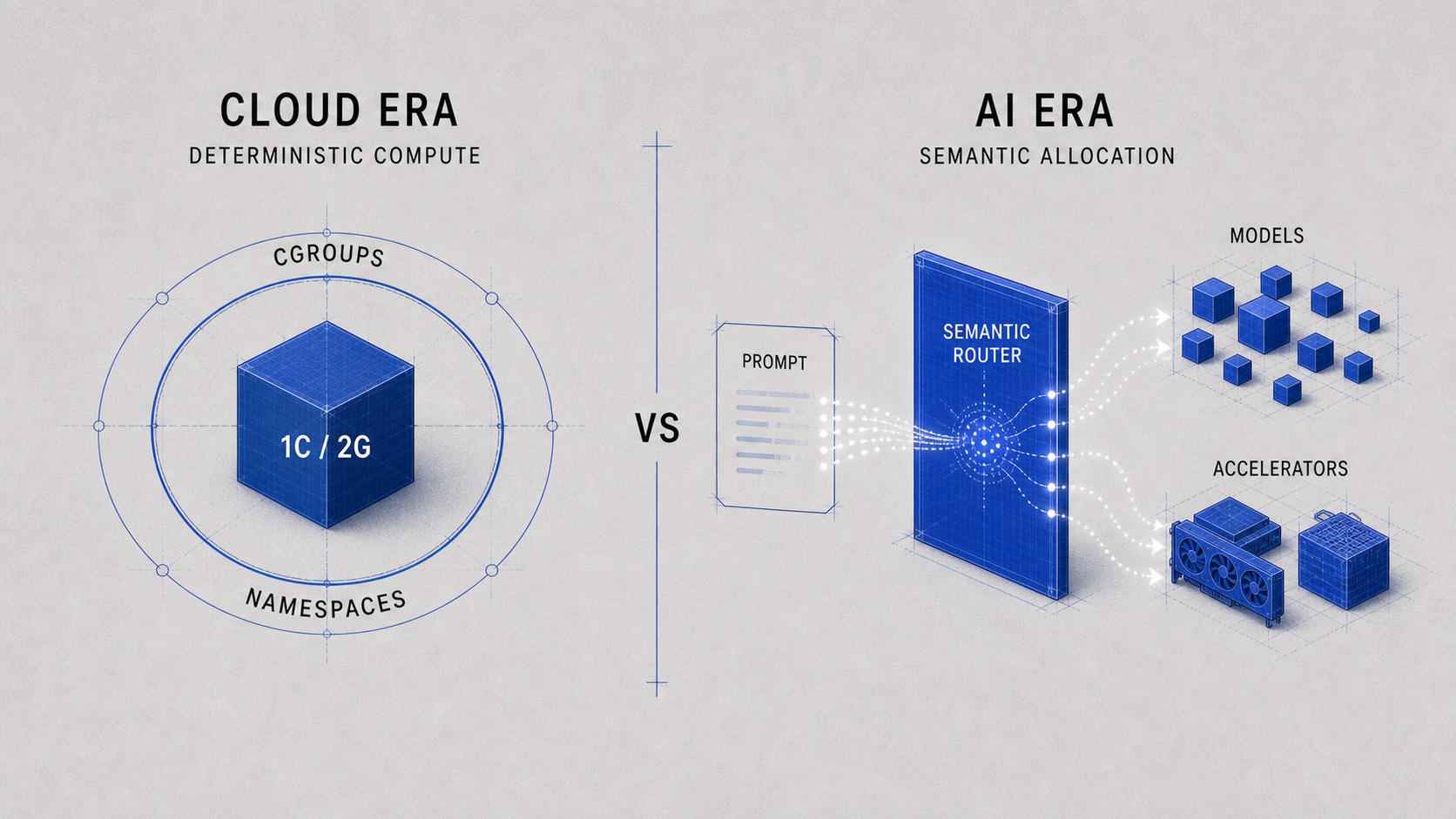
This is why semantic routing is closer to virtualization than to a load balancer. Cloud virtualization turned physical machines into isolated, secure, controllable pools of compute. Applications expressed requirements; the infrastructure handled placement, limits, isolation, and enforcement.
AI needs the same abstraction for intelligence. A user should not have to reason directly about the frontier model, the open model, the local model, the verifier, or the accelerator generation underneath. Those are the substrate: intelligence and energy. The interface should be preference and objective: quality target, latency budget, privacy boundary, cost ceiling, safety policy, sovereignty constraint, and risk tolerance.
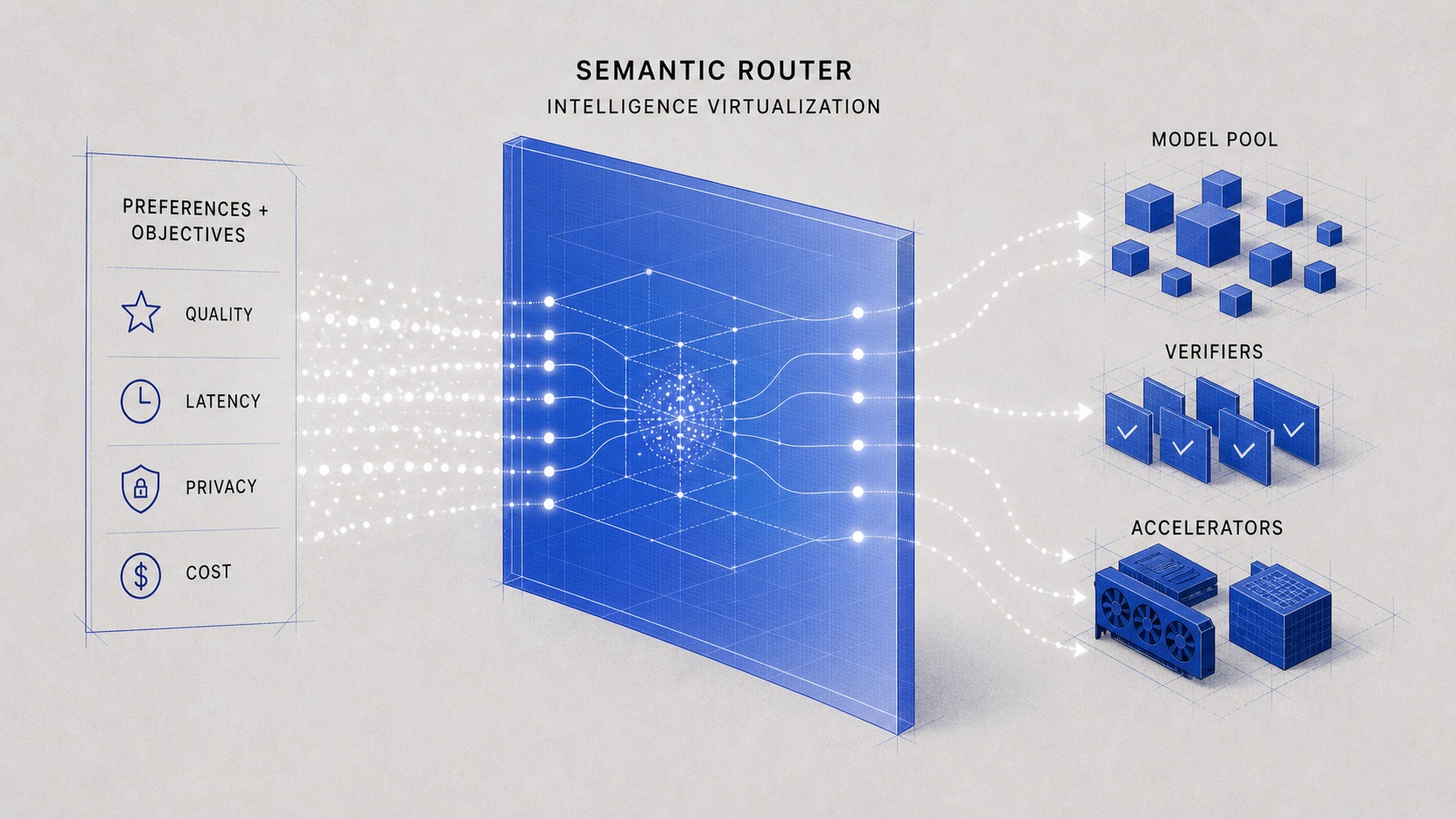
Every token begins as something physical: watts, hardware time, cooling, memory bandwidth, model capacity, and operational risk. Hardware and inference engines will keep making that conversion more efficient. But efficiency is incomplete if the system still spends its best intelligence on the wrong work.
This is the kind of control plane I think AI needs: one that reads workload signals, applies policy, respects privacy, understands the model and hardware pool, and decides how much intelligence a request is allowed to consume. In older systems, cgroups and namespaces made compute boundaries enforceable. AI needs the same kind of enforcement around intelligence: not only what can run, but how much reasoning, where, and under which constraints.
Frontier models remain essential. They expand what builders can imagine and show the rest of the stack what it must learn to support. But mature infrastructure is not defined by sending every request to the strongest resource. It is defined by knowing when that resource changes the outcome.
The first phase of AI was about access to intelligence. The next phase is about allocation.
Six months ago, I wrote that the second half of LLM routing would build collective intelligence. I would put it more sharply now:
The next stage of routing is where AI systems learn to budget intelligence.
Not just dollars. Watts, latency, privacy exposure, hardware scarcity, failure risk, and human trust.
That is why semantic routing is energy infrastructure: it defines the boundary of AI resource allocation before power becomes tokens.